Dataset & Benchmarks
One of the goals of Shifts is to provide a standardized collection of benchmarks for evaluation robustness of distributional shift and uncertainty quality across a range of tasks and data modalities. This collection of benchmarks consists of datasets taken directly from large-scale industrial sources and services where distributional shift is ubiquitous — settings as close to “in the wild” as possible. All of these data modalities and tasks are affected by distributional shift and pose interesting challenges with respect to uncertainty estimation.

Weather Forecasting
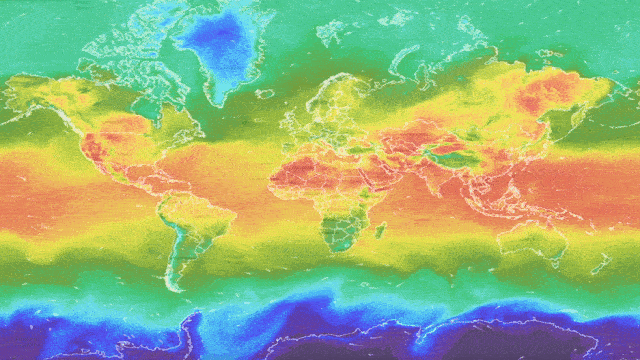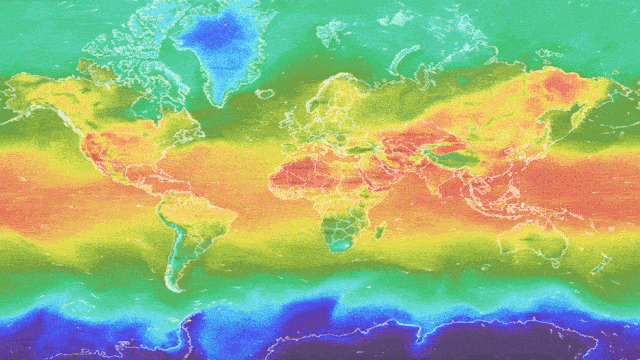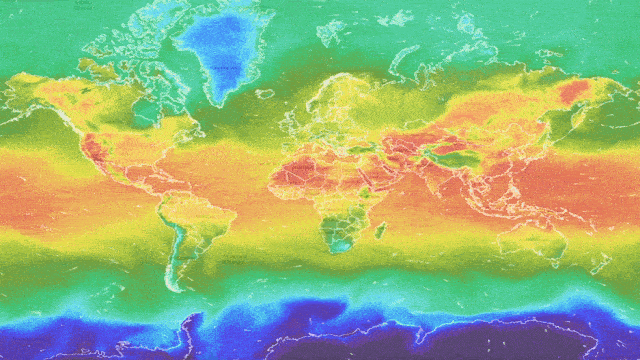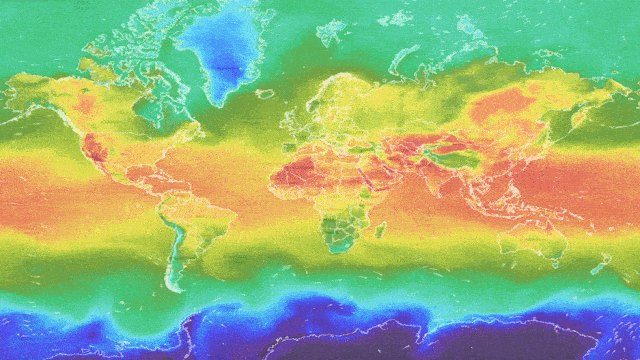
Motivation
People are increasingly using ML-based weather services to obtain forecasts about the weather at a specific desired location and time. People rely on these forecasts to be accurate so that they can confidently plan their day, weekends and holidays. However, the weather is a complex, highly non-stationary system which evolves over time — the weather on May 5th 2021 is likely to be different from May 5th 2022. Furthermore, ground-stations and meteorological radar are not uniformly distributed around the world — there is less information available about some locations. Ground-stations can also fail to communicate and transmit their readings. Finally, weather data is presented in heterogeneous tabular form, which not all ML models can handle well. ML weather forecasting systems need to be robust to shifts in time, location, and missing values and work well with tabular data to regularly produce reliable and accurate forecasts, especially in coastal and mountainous regions, where the weather can be hazardous. They should also indicate when they are unable to provide an accurate forecast. To better investigate robustness and uncertainty estimation in heterogeneous tabular data, the Yandex Weather service has provided the Shifts Weather Forecasting dataset. This data is also valuable as it represents similar challenges to the ones faced in high-risk applications, such as medical diagnostics and financial forecasting, which often contain a heterogeneous feature set, drift over time, non-uniform distribution over sub-populations and missing values.
Data Description
The Shifts Weather Prediction dataset contains both a scalar regression and a multi-class classification task. Specifically, at a particular latitude, longitude, and timestamp, one must predict either the air temperature at two meters above the ground or the precipitation class, given targets and features derived from weather station measurements and weather forecast models. The data consists of 10 million 129-column entries: 123 meteorological features, 4 meta-data attributes (time, latitude, longitude and climate type) and 2 targets — temperature (target for regression task) and precipitation class (target for classification task). It is important to note that the features are highly heterogeneous, i.e., they are of different types and scales. The full data is distributed uniformly between September 1 st, 2018, and September 1 st, 2019, with samples across all climate types. This data is used by Yandex for real-time weather forecasts and represents a real industrial application.
To provide a standard benchmark that contains both in-domain and shifted data, we define a particular “canonical partitioning” of the full dataset into training, development (dev), and evaluation (eval) datasets. The training, in-domain dev (dev_in) and in-domain eval (eval_in) data consist of measurements made from September 2018 till April 8th, 2019 for climate types Tropical, Dry, and Mild Temperate. The shifted dev (dev_out) data consists of measurements made from 8th July till 1st September 2019 for the climate type Snow. 50K data points are sub-sampled for the climate type Snow within this time range to construct dev_out. The shifted eval data is further shifted than the out-of-domain development data; measurements are taken from 14th May till 8th July 2019, which is more distant in terms of the time of the year from the in-domain data compared to the out-of-domain development data. The climate types are restricted to Snow and Polar. See paper for further details.
Download
You can access the data via our GitHub repository here.
License
Citation
@inproceedings{
malinin2021shifts,
title={Shifts: A Dataset of Real Distributional Shift Across Multiple Large-Scale Tasks},
author={Andrey Malinin and Neil Band and Yarin Gal and Mark Gales and Alexander Ganshin and German Chesnokov and Alexey Noskov and Andrey Ploskonosov and Liudmila Prokhorenkova and Ivan Provilkov and Vatsal Raina and Vyas Raina and Denis Roginskiy and Mariya Shmatova and Panagiotis Tigas and Boris Yangel},
booktitle={Thirty-fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track (Round 2)},
year={2021},
url={https://openreview.net/forum?id=qM45LHaWM6E}
}Machine Translation
Motivation
Translation services, such as Google or Yandex Translate, often encounter atypical and unusual use of language in their translation queries. This typically includes slang, profanities, poor grammar, orthography and punctuation, emojis and mixtures of different languages. This poses a challenge to modern translation systems. Therefore, it is important for models to both be robust to atypical language use to provide high-quality translations, as well as to indicate when they are unable to provide a quality translation. Furthermore, translation is inherently a structured prediction task, as there are dependencies between the tokens in the output sequence. Often we must make assumptions about the form of these dependencies. Depending on the assumptions made, it can be challenging to obtain a theoretically sound measure of uncertainty. The Yandex translation has collected a new dataset which features data taken from a translation service, as well as data sourced from Reddit. Thus, the Shifts Translation dataset contains examples of both clean, formal and highly atypical language usage. Altogether, this makes this an insightful benchmark for evaluating robustness and uncertainty quality on structured data. See paper for further details.
Data Description
The Shifts Translation dataset contains training, development (dev) and evaluation (eval) data, where each set consists of pairs of source and target sentences in English and Russian, respectively. As most production Neural Machine Translation (NMT) systems are built using a variety of general purpose corpora, we use the freely available WMT‘20 En-Ru corpus as training data. This dataset primarily focuses on parliamentary and news data that is, for the most part, grammatically and orthographically correct with formal language use. The dev and eval datasets consist of an “in-domain” partition matched to the training data, and a shifted partition, which contains examples of atypical language usage. The in-domain dev and eval sets are Newstest‘19 En-Ru and a news corpus from the GlobalVoices news service, respectively. For the shifted development data we use the Reddit corpus prepared for the WMT‘19 robustness challenge. This data contains examples of slang, acronyms, lack of punctuation, poor orthography, concatenations, profanity, and poor grammar, among other forms of atypical language usage. This data is representative of the types of inputs that machine translation services find challenging. As Russian target annotations are not available, we pass the data through a two-stage process, where orthographic, grammatical, and punctuation mistakes are corrected, and the source-side English sentences are translated into Russian by expert in-house Yandex translators. The development set is constructed from the same 1400-sentence test-set used for the WMT‘19 robustness challenge. For the evaluation set, we use the open-source MTNT crawler which connects to the Reddit API to collect a further set of 3,000 English sentences from Reddit, which is similarly corrected and translated. The shifted dev and eval data are also annotated with 7 non-exclusive anomaly flags.
Download
You can access the data via our GitHub repository here.
License
Citation
@inproceedings{
malinin2021shifts,
title={Shifts: A Dataset of Real Distributional Shift Across Multiple Large-Scale Tasks},
author={Andrey Malinin and Neil Band and Yarin Gal and Mark Gales and Alexander Ganshin and German Chesnokov and Alexey Noskov and Andrey Ploskonosov and Liudmila Prokhorenkova and Ivan Provilkov and Vatsal Raina and Vyas Raina and Denis Roginskiy and Mariya Shmatova and Panagiotis Tigas and Boris Yangel},
booktitle={Thirty-fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track (Round 2)},
year={2021},
url={https://openreview.net/forum?id=qM45LHaWM6E}
}Vehicle Motion Prediction
Motivation
The autonomous driving domain has strict safety requirements, ubiquitous distributional shift and the risks associated with errors are high. During development, most self-driving companies concentrate their fleet in a few locations. Robustly generalizing from old locations to new ones is challenging, as new locations can differ in routes, driving styles, types of cars, road signs and so on. Thus, fleets face distributional shift when they begin operating in new locations. It is also critical for a planning model to recognize when this transferred knowledge is insufficient upon encountering unfamiliar data. For example, when the model’s uncertainty is high, the vehicle can exercise extra caution or request assistance from a remote operator.
Motion prediction is among the most important problems in the autonomous driving domain. It involves predicting the distribution over possible future states of other agents around the self-driving car at a number of moments in time to avoid planning a potential collision. This problem is complicated by the fact that the future is inherently uncertain. For example, we cannot know the high-level navigational goals of other agents, or even their low-level tendency to turn right or left at a T-junction if they fail to indicate. In order for the planning module to make the right decision, this uncertainty must be precisely quantified. This is complicated by motion prediction being a continuous structured prediction task, making it non-trivial to obtain meaningful measures of uncertainty. Altogether, this makes motion prediction an interesting task for investigating uncertainty estimation and robustness to distributional shift. To this end, the Yandex Self-Driving Group has provided the Shifts Vehicle Motion Prediction dataset to be used for examining the implications of distributional shift in self-driving vehicles.
Data Description
The Shifts Motion Prediction dataset was collected by the Yandex Self-Driving Group (SDG) fleet and is the largest vehicle motion prediction dataset released to date, containing 600,000 scenes. These scenes span six locations, three seasons, three times of day, and four weather conditions. Each scene includes information about the state of dynamic objects and an HD map. Each scene is 10 seconds long and is divided into 5 seconds of context features and 5 seconds of ground truth targets for prediction, separated by the time T = 0. The goal is to predict the movement trajectory of vehicles at time T ∈ (0, 5] based on the information available for time T ∈ [−5, 0]. The data contains training, development (dev) and evaluation (eval) sets. In order to provide a standardized benchmark, we define a canonical partitioning. Distributionally shifted dev data is taken from Skolkovo, Modiin, and Innopolis. Distributionally shifted eval data is taken from Tel Aviv and Ann Arbor. We also remove all cases of precipitation from the in-domain sets, while distributionally shifted datasets include precipitation. See paper for further details.
Download
You can access the data via our GitHub repository here.
License
Citation
@inproceedings{
malinin2021shifts,
title={Shifts: A Dataset of Real Distributional Shift Across Multiple Large-Scale Tasks},
author={Andrey Malinin and Neil Band and Yarin Gal and Mark Gales and Alexander Ganshin and German Chesnokov and Alexey Noskov and Andrey Ploskonosov and Liudmila Prokhorenkova and Ivan Provilkov and Vatsal Raina and Vyas Raina and Denis Roginskiy and Mariya Shmatova and Panagiotis Tigas and Boris Yangel},
booktitle={Thirty-fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track (Round 2)},
year={2021},
url={https://openreview.net/forum?id=qM45LHaWM6E}
}Vessel Power Estimation
Motivation
Maritime transport delivers around 90% of the world’s traded goods, emitting almost a billion tonnes of CO2 annually and increasing. Energy consumption varies greatly depending on the chosen routes, speeds, operation and maintenance of ships. The complex underlying relationships between are not fully known or taken into account at the time these decisions are made, leading to significant fuel waste. Training accurate power consumption models can help significantly reduce costs and emissions. However, significant distributional shifts can be expected to occur between the real use cases of models and the data used to train and evaluate them. Weather and sea conditions that affect vessel power consumption are highly variable based on seasonality, geographical location and vessel state and cannot all be fully measured. Furthermore, data relevant to predicting a vessel’s power consumption is typically presented in heterogeneous tabular form, which can be challenging for some ML models to handle. Inaccurate power prediction and the resultant errors in fuel planning and optimisation can be considerably costly and potentially hazardous. Thus, the development of uncertainty-aware and robust models is essential to enable the effective deployment of this technology to reduce the carbon footprint of global supply chains. DeepSea has provided the Shifts Vessel Power Estimation dataset to facilitate investigation of distributional shift in shipping and the development of robust models.
Data Description
The Shifts Vessel Power Consumption dataset features a scalar regression task that involves predicting the current power consumption of a merchant vessel given features describing the vessel and weather conditions. The dataset consists of 10 measurements sampled every minute from sensors on-board a merchant vessel over a span of 4 years, cleaned and augmented with weather data from a third-party provider. The target is the vessel’s main engine shaft power, i.e. the energy it expends per second to maintain its speed. The task is to predict this power (which in turn can be used to predict fuel consumption given an engine model) from the vessel’s speed, draft, time since last dry dock cleaning and various weather and sea conditions. Thus, altogether, each record contains 12 entries — 10 features, 1 time index and 1 target. Distributional shift arises from hull performance degradation over time due to fouling, sensor calibration drift, and variations in non-measured sea conditions such as water temperature and salinity, as well as sensor noise, measurement and transmission errors, and uncertainty in historical weather. Additionally, all this varies in different regions and times of year.
The Shifts Vessel Power estimation datasets contains two major components — a ‘real’ and a ‘synthetic’ dataset. The real dataset contains features and power consumption recorded from a real vessel. The synthetic dataset contains the same features, but with power consumption estimates produced by a physics-based model. Additionally, the synthetic dataset contains a ‘generalization set’, which contains samples from the convex hull of feature values. The synthetic data is meant for model exploration and development, while the real dataset is meant to represent a newly introduced vessel for which a power usage estimation model needs to be developed. To provide a standard benchmark, the both the real and synthetic data was partitioned along two dimensions: wind speed and time. Wind speed serves as a proxy for unmeasured components of the sea state, while partitioning in time aims to capture effects such as fouling and sensor drift. 5 subsets are made — train, in-domain development and evaluation and shifted development and evaluation sets. In addition, the synthetic dataset also contains a large generalization set. See paper for further details.
Download
Data is available on Zenodo.
License
Citation
@article{
malinin2022shifts,
title={Shifts 2.0: Extending The Dataset of Real Distributional Shifts},
author={Malinin, Andrey and Athanasopoulos, Andreas and Barakovic, Muhamed and Cuadra, Meritxell Bach and Gales, Mark JF and Granziera, Cristina and Graziani, Mara and Kartashev, Nikolay and Kyriakopoulos, Konstantinos and Lu, Po-Jui and others},
journal={arXiv preprint arXiv:2206.15407},
year={2022}
}White Matter Multiple Sclerosis Lesion Segmentation
Motivation
Multiple Sclerosis (MS) is a debilitating, incurable and progressive disorder of the central nervous system that negatively impacts an individual’s quality of life. Estimates claim that every five minutes a person is diagnosed with MS, reaching 2.8 million cases in 2020 and that MS is two-to-four times more prevalent in women than in men. Magnetic Resonance Imaging (MRI) plays a crucial role in the disease diagnosis and follow-up. However, manual annotations are expensive, time-consuming, and prone to errors. Automatic, ML-based methods may introduce objectivity and labor efficiency in the tracking of MS lesions. However, the availability of training images for machine learning methods is limited. No publicly available dataset fully describes the heterogeneity of the pathology. Furthermore, changes in MRI scanner vendors, configurations, imaging software and medical personnel leads to significant variability in the imaging process. These differences, which are exacerbated when images are collected from multiple medical centers, represent a significant distributional shift for ML-based MS detection models, reducing the applicability and robustness of automated models in real-world conditions. Additionally, as segmentation is a structured prediction task, obtaining meaningful estimates of uncertainty at the voxel, lesion and patient levels can be non-trivial. The development of robust MS lesion segmentation models capable of yields information estimates of uncertainty is necessary to bring improvements in the quality and throughput of the medical care available to the growing number of MS patients. OFSEP, Johns Hopkins University, the University of Basel and the University of Ljubljana have contributed to the Shifts White Matter Lesion Segmentation Dataset for the purposes of developing reliable and robust MS lesion segmentation models.
Data Description
The Shifts White Matter MS lesion segmentation dataset features a task that involves the generation of a 3D segmentation mask of brain lesions in multi-modal MRI images. Given the 3D MRI scans of the brain, a model classifies each voxel into lesion and non-lesion tissue. Each sample in the dataset consists of a 3D brain scan taken using T1-weighted and Fluid-Attenuated Inversion Recovery (FLAIR) contrasts that have undergone pre-processing including denoising, skull stripping, bias field correction and interpolation to a 1mm isovoxel space. The ground-truth segmentation mask, also interpolated to the 1mm isovoxel space, is obtained as a consensus of one or more expert annotators. The dataset contains scans from multiple clinical centers: Rennes, Bordeaux, Lyon, Ljubljana, Best and Lausanne. Patient scans from different locations vary in terms of scanner models, local annotation guidelines, scanner strengths and resolution of raw scans. For standardized benсhmarking we have created a canonical partitioning of the data into in-domain train, development (dev) and evaluation (eval) sets as well as shifted development and evaluation sets. For locations containing multiple scans per patient care is taken to ensure the multiple scans are kept separate between Train/Dev and Eval. The locations Rennes, Bordeaux, Lyon and Best are treated as in-domain and the locations Ljubljana and Lausanne are treated as publicly available and held-out distributionally shifted development and evaluation sets, respectively. The Lausanne portion of the data will not be publicly released, but it will be possible to freely evaluate models on it via Grand-Challenge. See paper for further details.
License
Part Creative Commons CC BY NC SA 4.0, part credentialized Access via Zenodo with OFSEP data usage agreement
Citation
@article{
malinin2022shifts,
title={Shifts 2.0: Extending The Dataset of Real Distributional Shifts},
author={Malinin, Andrey and Athanasopoulos, Andreas and Barakovic, Muhamed and Cuadra, Meritxell Bach and Gales, Mark JF and Granziera, Cristina and Graziani, Mara and Kartashev, Nikolay and Kyriakopoulos, Konstantinos and Lu, Po-Jui and others},
journal={arXiv preprint arXiv:2206.15407},
year={2022}
}






